루비에서 string-similarity로 문자열 퍼센트로 비교하기(Comparing string-similarity percent in Ruby)
한 두달? 정도전에 루비 라이브러리중에 괜찮은거 하나 봐둔게 있었느데, 이제서야 글로 작성하네요. 문자열 비교 라이브러리인데, 매칭률을 퍼센트로 뽑을 수 있습니다. 활용처가 많을듯하여 메모해둡니다.
Install
gem install string-similarity
Code
require 'string/similarity'
p("foo bar : "+String::Similarity.cosine('foo', 'bar').to_s)
p("hangul hahwul : "+String::Similarity.cosine('hangul', 'hahwul').to_s)
p("test test : "+String::Similarity.cosine('foo', 'foo').to_s)
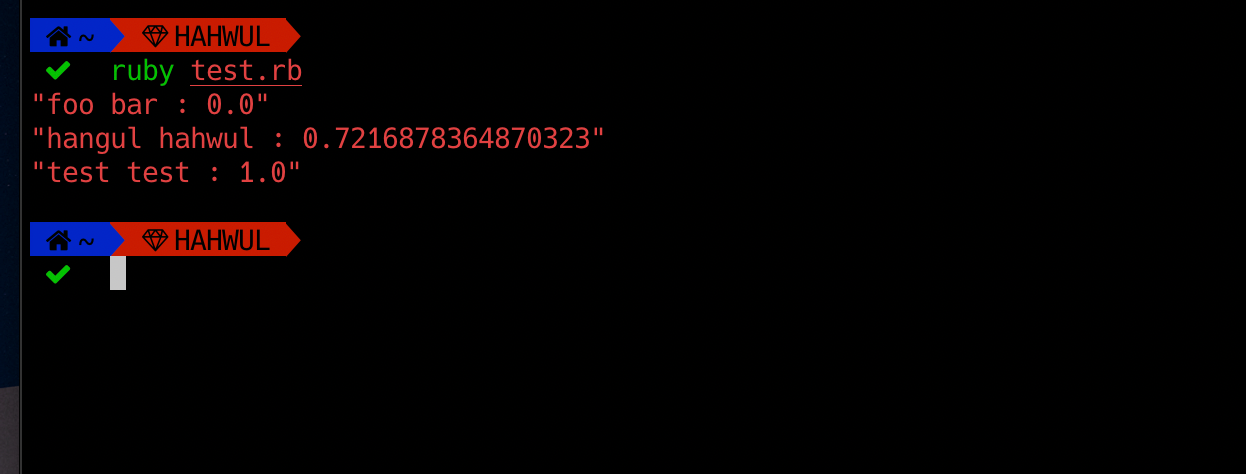
ruby test.rb
"foo bar : 0.0"
"hangul hahwul : 0.7216878364870323"
"test test : 1.0"
어디서 활용하려고?
우선 라이브러리를 찾게된 계기가 스캐너 개발 관련해서인데요, 스캔 시 공격코드로 입력된 문자열이 어느정도 동일하게 노출되는지를 파악하려다보니 이 라이브러리까지 오게되었습니다. diff 자체의 기능 이외에도, 취약점 스캐너 계열에선 탐지율 향상에 조금 도움이 있을 것 같습니다.
reflected xss의 경우 공격 페이로드가 어떻게 노출되고 있는가에 따라서 정/오탐이 나뉠텐데, 이걸 단순 문자열 매칭으로 하면 탐지율이 많이 떨어집니다. 그래서 얼마나 유효한지를 점수를 두고, 특정 패턴이 나올때 높게주어 탐지율을 올릴 수 있는데, 이때 문자열 비교과정이 굉장히 귀찮습니다. 잘 활용하면 % 단위로 예를들어, 70% 이상인 경우에 취약으로만 주어도, 이전에 놓쳐진 페이로드들도 많이 잡히지 않을까 싶습니다. 이러한 규칙들을 여러가지로 중첩하면 분명 이전보다 탐지율 측면에선 이득이지 않을까 싶습니다.
또 하나 생각났던건 요청에 따른 페이지의 차이? 를 구해서 흐름을 바꾸거나 결과를 제어할 수 있는 의미있는 파라미터들을 걸러내는데 쓰일 수 있을 것 같습니다. 결국 진단에서 쓸모있는 파라미터, 쓸모없는 파라미터를 빨리 식별하는 것도 중요한데(삽질 방지..) 조금이나마 도움되지 않을까 싶습니다.